国庆时间看到作者出版了一本正则表达式的书,因为之前一直对模板好奇,于是就去作者的网盘里面下载了这一本书的pdf版观看。最近看完之后觉得作者写的很棒,弥补了自己很多正则的基础 知识。附上链接《JavaScript 正则表达式迷你书》问世了!。
文章主要记录了一下自己的学习心得
1. 复杂的正则表达式可以由几个简单的正则表达式组合而成
记得之前每次写密码验证的时候,总希望一个正则表达式搞定全部的情况,看完书后觉得原来没有必要。
以密码验证为例出题:
密码长度 6-12 位,由数字、小写字符和大写字母组成,但必须至少包括 2 种字符。大家可以想一下怎么实现。
书中一开始得出了一个非常复杂的正则表达式,但是其实后期维护修改未必简单,而且换一个同事来维护,刚开始理解也很辛苦。
可以看到,第一种对于我这种刚开始实战不多的,颇有一点炫技的表现(也有可能是我太菜)。第二种一看,会舒服很多,高可读性和高可维护性。
我个人认为在团队合作中,第二种对于后期伙伴的维护应该是更佳的。
2. ?的各个含义
在看书的时候,因为之前正则的基础很薄弱,看见书中频频出现的?用在不同地方实现不一样的效果,我是一脸懵逼,经常要上百度看一下?用在这里表示什么意思。这里小总结一下
2.1 本身符号“?”
表达自身一个“?”字符,但是因为?在正则表达式中的作用太多了,所以当它需要表达自身的时候,需要进行一次转义
2.2 表示匹配次数,
这是常见的第一种用法,允许重复匹配的次数,0次或者1次。
例子
2.3 表示懒惰匹配
这是常见的第二种用法,因为正则表达式默认是贪婪匹配的,所以很多时候我们会在某组匹配字符后加一个问号表示非贪婪匹配
例子
2.4 配合字符实现位置匹配
书中讲到了 这么一句话
正则表达式是匹配模式,要么匹配字符,要么匹配位置。请记住这句话。
关于”位置”这个概念的理解推荐看书中的第二章
而当你匹配位置的时候,两个匹配位置的正则表达式就非常关键了。
(?=p),其中 p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配 p。
而 (?!p) 就是 (?=p) 相反的意思,比如:
这两个用法在数字格式化的时候有非常大的用处。给大家出个题目吧,如何实现数字的千位分隔符表示。比如讲1234567转化为12,345,678。
大家思考一下
….
….
….
答案
具体实现看不懂还是推荐去看原书,作者写的很好,我相信对大家帮助肯定也很大。
2.5 非捕获模式
还有最后一种不怎么常见(可能是没怎么见过)的用法(?:),表示非捕获模式。我是这么理解的(不知道自己理解的对不对),就是当你遇到匹配的字符时,它并没有马上捕获匹配的内容,并且记录下拉,而是继续匹配下去作为为整体匹配服务。讲的不好,大家还是看例子实在吧(手动捂脸)。
例子
大家可以注意到第一个括号里面的a并没有被提取出来,但是整体匹配的字符时有a的。这就是我理解的非捕获模式,为整体存在的匹配。
3. 回溯的学习
性能和效率始终是绕不开的一环,文中提到回溯造成原因我感觉主要是由2点造成的,
- 一是由于匹配默认是贪婪的
- 二是由于匹配有时候是懒惰的。(使用分支情况下)
3.1 贪婪匹配造成的回溯
先说第一种情况,贪婪匹配造成的回溯,举个书中的例子
当用此正则表达式去匹配字符串的时候,发现最后无法完成整体匹配的时候,会不断回吐一个字符再次去尝试整体正确的匹配。大家可以结合下图理解。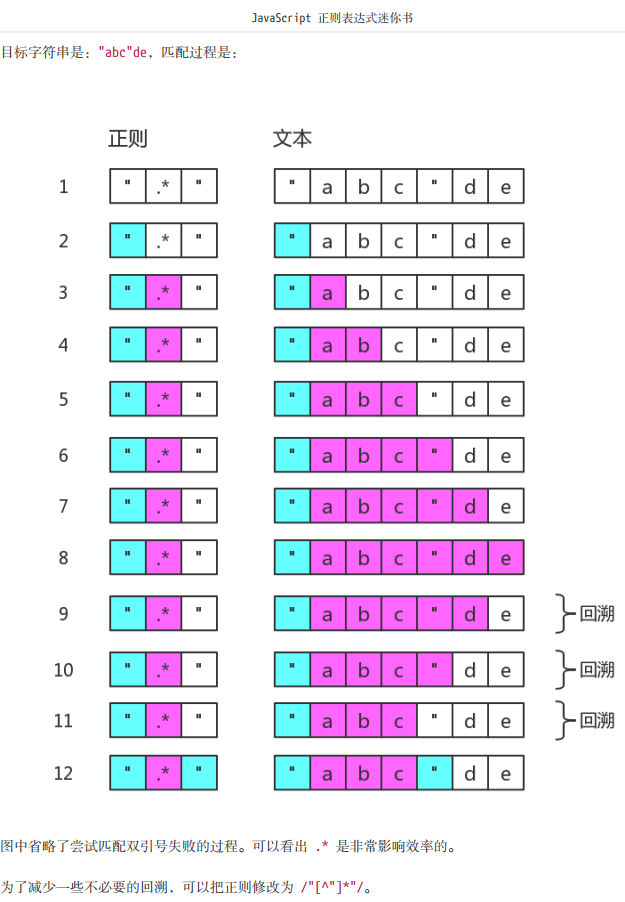
书中最后讲到回溯是非常影响效率的,但是自己在写例子测试的时候,发现其实时间基本上没有任何差别,不知道是不是因为自己测试的正则比较简单,还是浏览器现在对于正则的优化做的比较好,总之没有达到书中说的到非常影响效率的程度。
效率对比例子
对于这种回溯的解决方法来说:
- 方法1 :写尽量正确的匹配。像上面例子中的修改版就是这种解决方法,
- 方法2 :尽可能少的匹配。比如加个惰性量词“?”。(其实就是尽量减少贪婪匹配)
3.2懒惰匹配造成的回溯
然而并不是所有回溯的情况都是由贪婪造成的。比如当我们在使用分支匹配的时候。
例子
当我们用/can|candy/去匹配字符串 “candy”,得到的结果是 “can”,因为分支会
一个一个尝试,如果前面的满足了,后面就不会再试验了。但是如果我们的目标字符串是“candy”的时候,那怎么办呢。
例子
大家可以先看图理解一下懒惰造成的回溯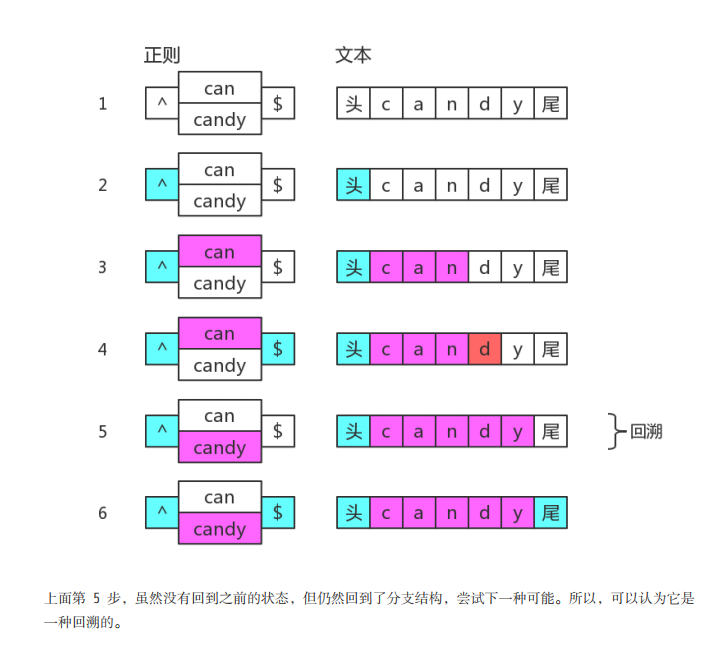
4. 跟正则有关几个正则方法
字符串对象和正则对象提供了很多跟正则有关的基础方法,很多方法都都有很好的使用场景。
4.1 RegExp#test
比如我在表单验证的场景里,用户每次输入值我需要进行判断用户是否输入正确,我可是使用regex.test()方法来确定是否给用户提示
只允许输入数字
4.2 String#replace
这个replace方法用处实在是太大了,已经到了可以单开一篇的地步了,大家可以前往这里去看MDN上replace的文档,这里就不详细介绍了。这里写个简单的例子
最简单的模板编译
4.3 String#search
这个方法感觉和indexOf效率有一些相似,都是寻找符合匹配的下标。不过indexOf方法是为字符串使用的,而search是为正则表达式实现的
4.3 String#split
字符串的split方法同样支持正则表达式进行切割
4.4 String#match
这个方法更多是为了提取匹配内容而存在的。当你的正则表达式里面有小括号()的存在时,match方法可以帮你提取出字符串中符合括号正则的表达式。